
en
Predictive Analytics in Commerce
Step 1. Build the best possible churn model
It is time to create your own churn model. Start by creating a random forest on a subset of the data, and then (just like Nienke recommends) build a random forest on the whole dataset (be aware that this might be more time-consuming).
Do you get similar results when you use your whole dataset? And do the results seem logical to you?
Step 2. Elevator pitch
Set up a short presentation (an elevator pitch) to convince your boss to set up a retention campaign based on the churn model you just built. Mention the work you have done, what problem you are trying to solve and how you think you can solve it.
Need a little guidance on how to setup a good elevator pitch? Watch this movie and you are ready to go: https://www.youtube.com/watch?v=-t1ar_IpmUU
Stabilizes at 350 decision trees.
Lowest Out-of-bag error at 8 mtry
Familiy Structure is the most important variable determining whether the customer is likeli to churn or not.
%IncMSE IncNodePurity
CustomerDurationMonths 40.083756 489.165206
CustomerDurationYears 32.640204 411.730749
Gender 18.825873 10.588889
Age 97.162641 235.325966
FamilyStructure 201.252527 2145.402163
Province 32.327481 81.920704
HasEmail 22.573780 89.147013
HasPhoneHome 9.050671 4.658520
HasPhoneMobile 20.562747 69.906089
PurchasingPowerInhabitant 20.454292 52.593159
PurchasingPowerInhabitantIndex 21.643549 44.462053
PurchasingPowerHousehold 18.643876 36.941573
PurchasingPowerHouseholdIndex 16.517416 35.069661
LastCampaignDate 66.656566 208.659288
Income 37.775483 618.621441
OnlinePortalUsage 34.047989 69.057824
NPS 10.760620 14.299298
InboundCall 30.335883 31.193178
OutboundCall 12.870076 9.195475
OnlineCoverageChange 12.325812 8.391263
InboundEmail 3.385531 5.073329
OutboundEmail 4.270863 6.172511
TriggerPremiumDecrease 9.289418 4.505686
TriggerPremiumIncrease 3.281648 2.203944
AUC = 0.9196565
% Var explained: 58.35
The AUC and R2 seen combined makes it a good model.
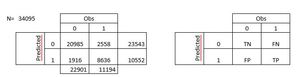
Accuracy: Overall, how often is the classifier correct? 87%
Misclassification Rate: Overall, how often is it wrong? 13%
True Positive Rate: When it's actually yes, how often does it predict yes? 77%
False Positive Rate: When it's actually no, how often does it predict yes? 8%
Specificity: When it's actually no, how often does it predict no? 92%
Precision: When it predicts yes, how often is it correct? 82%
Prevalence: How often does the yes condition actually occur in our sample? 33%
When looking at the confusion matrix, the accuracy is 87 % and the misclassification rate only 13 %. This makes it relatively strong model to use when determining which customer’s that are likely to churn and therefore make an effort to retain these.
Join with: